
TL;DR
AI isn’t a feature wave; it’s a platform reset. Stacks, workflows, and even “what is an app?” get re-written. The winners will:
design for multi-model, agentic orchestration,
run a distillation factory to create small, task-specific models,
ship an AI app server with memory, search, safety, and evals as first-class services, and
optimize for workflow adoption metrics over demos.
1) This Is a Platform Reset, Not a Feature
Every layer is being re-litigated—from storage formats to UI metaphors.
Layer | Yesterday | Today (AI-native) |
|---|---|---|
Compute | CPU-heavy + some GPU | Accelerator-first (GPUs/NPUs), elastic |
Storage | Row/column files | Model + embedding + artifact stores |
Indexing | B-trees, BM25 | Hybrid semantic indices with RAG |
Runtime | Microservices | Multi-agent orchestration with tool adapters |
UX | Forms & menus | Intent-first chat + “living artifacts” |
Takeaway: plan migrations like you would for a cloud move. You need new foundations, not bolt-ons.
2) Compounding S-Curves: Why “Good Enough” Won’t Hold
Progress is stacking across hardware, systems, model architecture, inference kernels, and app patterns. The compounding effect means order-of-magnitude leaps every few quarters.
Implication: Design for continuous swap-outs (models, kernels, indexes). Lock-in is now a process choice, not just a vendor choice.
Engineering pattern: “Hot-swappable intelligence”
Contract-first tool APIs
Model registry with A/B routing
Shadow traffic + progressive rollout
Cost/latency/quality budgets enforced at the gateway
3) Multi-Model, Agentic Apps: One Brain, Many Adapters
Single-model apps were the starter kit. Real products orchestrate multiple specialized models/agents with clear responsibilities and a context contract per task.
Minimal Context Contract (JSON)
{ "intent": "Plan a 3-day city trip under ₹50k", "required_signals": ["user_profile", "inventory", "policies", "weather", "constraints"], "caps": {"tokens": 32_000, "freshness": "24h", "cost_budget_usd": 2.00}, "guarantees": {"provenance": true, "fallbacks": ["cached_plans", "rules_engine"]}, "tool_order_hint": ["availability", "pricing", "policy", "personalization"]}Why it matters: Orchestration beats model choice. Sequence, memory, and evaluation do the heavy lifting.
4) Open + Closed: Choose Both, Standardize the Interfaces
You will need frontier models for capability and open models for control, cost, and distillation.
Strategy:
Define a Model Capability Contract (input schema, output schema, latency/cost SLOs).
Route by task + budget + sensitivity.
Keep the tooling identical (prompt templates, safety, evals) regardless of model family.
5) The Distillation Factory: Small Models, Big Impact
Large models explore; small models execute. Treat distillation like CI/CD for intelligence.
Distillation Pipeline
Select: choose a base frontier/open model for teacher signals.
Sample: generate targeted task data + hard negatives.
Distill: train student on task distributions + guardrails.
Align: add policy/safety layers (RLHF/DPO/rules).
Evaluate: regression tests on functional + safety + cost.
Deploy: tenant- or team-scoped endpoints with budgets.
Refresh: weekly micro-distills on new edge cases.
Output manifest (YAML)
task: "Itinerary-Scorer-v3"student_model: "sm-8b-q4"teacher_models: ["frontier-x", "open-70b"]metrics: quality: {pass@k: 0.78, bleu: 0.31} safety: {blocked_rate: <1%} latency_ms_p95: 220 cost_usd_per_1k: 0.002rollout: {tier: "tenant", region: "ap-south-1"}6) Ship an AI App Server, Not Just a Chatbot
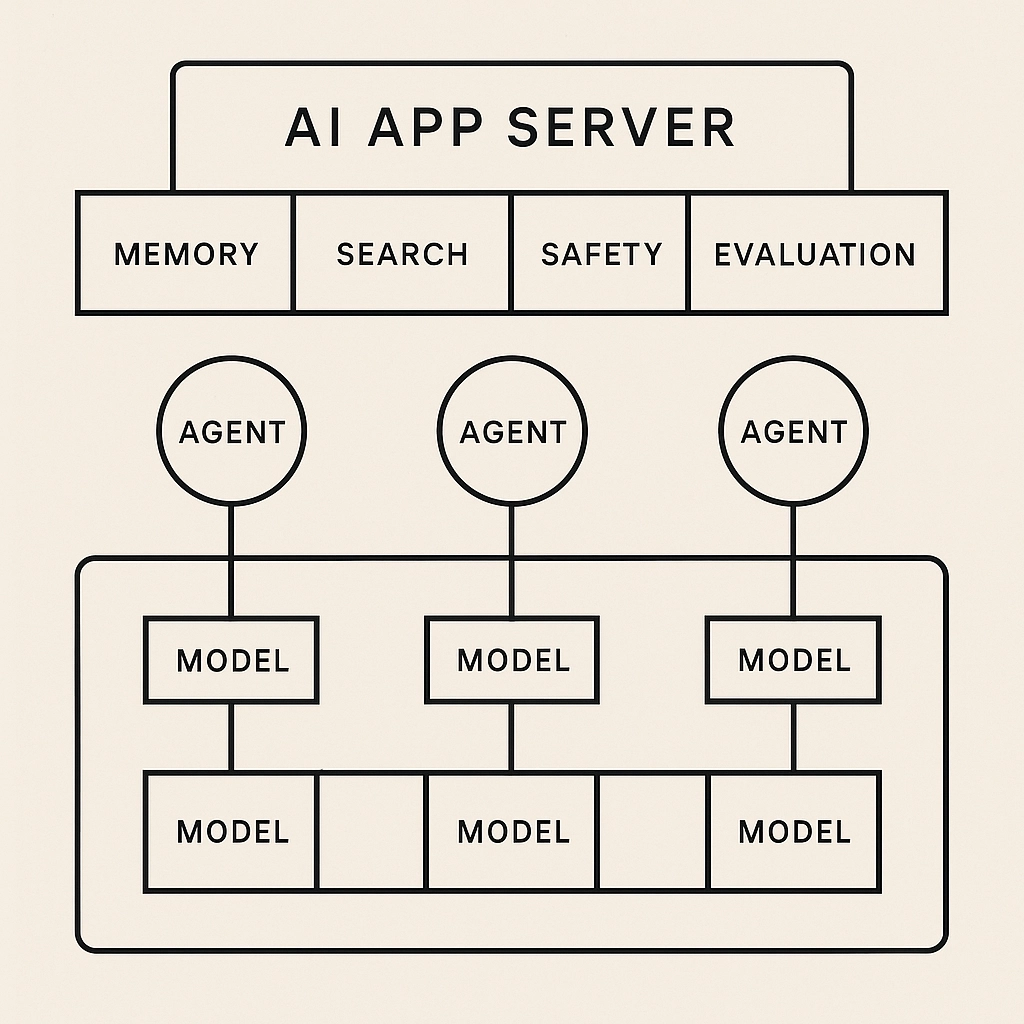
Every serious product needs an AI app server—a thin layer that standardizes shared services:
Core Services
Memory (short/long-term, tenant-scoped)
Search/RAG (hybrid retrieval, chunking & stitching)
Safety (input/output filters, red-team hooks)
Evaluation (offline + online, golden sets, LLM-as-Judge)
Observation (traces, costs, token & tool usage)
Policy (PII handling, locality, audit logs)
Developer Ergonomics
Prompt/version registry, feature flags for prompts
Canary + guardrail budgets (tokens, $, p95 latency)
Analytics on accept-rate, clarification loops, groundedness
7) From Autocomplete to Agents: Measure Workflow, Not Demos
Productivity gains come when AI is embedded where the work already lives (repos, docs, CRM), not in yet another tab.
Adoption metrics to watch
Contribution share: % of actions/artifacts AI-authored
Accept rate: % AI suggestions accepted (by task type)
Cycle time: lead time from intent → artifact
Escalation rate: % tasks requiring human takeover
Clarification ratio: follow-up turns per successful task
Spend efficiency: quality points per $ and per ms
8) Living Artifacts: When Docs Become Apps
AI melts the boundary between document, app, and website. Start from intent, end with a mutable artifact that contains data, logic, and UI.
Design principles
Composability: artifact = data + tools + policy view
Traceability: embedded provenance and diffs
Roles: viewer/editor/approver agents + humans
Exports: snapshot to PDF/CSV/API for compliance
9) AI as a New Factor of Production
Think of AI as computational labor + cognition—a genuine production input. The tech is only half the story; the other half is management and workflow redesign.
Org Readiness Ladder
Assist: autocomplete & chat in existing tools
Advise: AI proposes, human disposes (with evidence)
Act: AI executes within policy-bounded lanes
Autonomize: AI owns well-specified outcomes with SLAs
Promote teams up the ladder by policy, not vibes.
10) The Builder’s Playbook (90 Days)
Month 1 — Foundations
Pick 3 high-leverage tasks; write context contracts.
Stand up the AI app server (memory, RAG, safety, evals).
Create golden datasets + a quality dashboard.
Month 2 — Shipping
Ship multi-model routing with budget guardrails.
Add shadow mode for a distilled student on one task.
Turn on observability: traces, cost, p95, error taxonomies.
Month 3 — Scaling
Graduate 1 task to Act (bounded autonomy).
Launch weekly micro-distills.
Tie team OKRs to adoption metrics (accept-rate, cycle time).
11) Anti-Patterns to Avoid
Model monogamy: optimizing one model instead of the system.
Prompt spaghetti: no versioning, no tests.
Demo-driven development: features without workflow change.
Cost surprises: no budgets, no per-task accounting.
RAG theater: retrieval that isn’t evaluated or grounded.
12) Governance That Moves as Fast as You Ship
Data contracts: PII classes, retention, locality per task.
Safety tuning loop: human review queues, red-team replays.
Policy slots: enforceable at gateway (who/what/where).
Citations: every artifact carries evidence links.
Kill-switches: circuit breakers on cost, error spikes, drift.
13) A Simple Mandate
Ship one agent this quarter that does real work under policy:
starts with an intent,
calls the right tools in the right order,
produces a living artifact with provenance,
improves weekly via distillation + evals, and
proves its value in adoption metrics, not applause.
That’s the path from experiments to an AI-native company.
Comments